.jpg)
参考:
https://zhuanlan.zhihu.com/p/25994179
1 什么是KNN
kNN(k-nearest neighbor classification),即k近邻算法。
给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实例分类到这个类中。
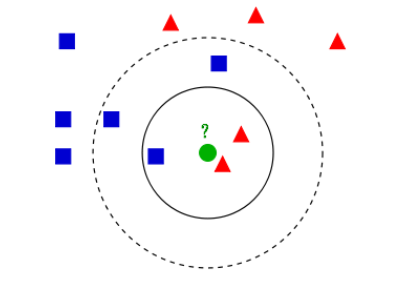
图中,绿色的圆所标示的数据则是待分类的数据,我们根据k近邻的思想来给绿色圆点进行分类。
- 如果K=3,绿色圆点的最邻近的3个点是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
- 如果K=5,绿色圆点的最邻近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
k值既不能过大,也不能过小,我们一般选取一个较小的数值,通常采取 交叉验证法来选取最优的k值。(也就是说,选取k值很重要的关键是实验调参,类似于神经网络选取多少层这种,通过调整超参数来得到一个较好的结果)
2 距离
定义中所说的最邻近是如何度量呢?我们怎么知道谁跟测试点最邻近。这里我们一般用欧式距离来计算。
数据可以理解成是由几个维度定义成的,这几个维度可以看成是几个坐标轴,数据在空间中的位置就是这几个坐标定义成的点,那么在计算数据之间的距离的时候,就是在计算空间之中两点的距离。
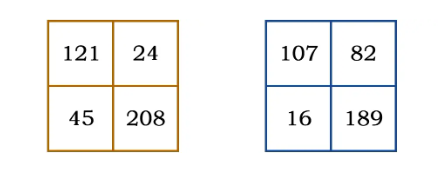
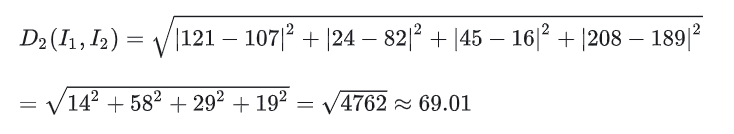
3 特征归一化
用一个人身高(cm)与脚码(尺码)大小来作为特征值,类别为男性或者女性。我们现在如果有5个训练样本,分布如下:
A [(179,42),男] B [(178,43),男] C [(165,36)女] D [(177,42),男] E [(160,35),女]
很容易看到第一维身高特征是第二维脚码特征的4倍左右,那么在进行距离度量的时候,我们就会偏向于第一维特征。这样造成俩个特征并不是等价重要的,最终可能会导致距离计算错误,从而导致预测错误。
现在我来了一个测试样本 F(167,43),让我们来预测他是男性还是女性,我们采取k=3来预测。
下面我们用欧式距离分别算出F离训练样本的欧式距离,然后选取最近的3个,多数类别就是我们最终的结果,计算如下:
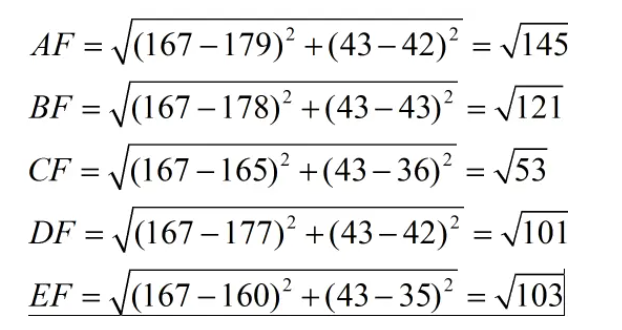
最近的前三个分别是C,D,E三个样本,那么由C,E为女性,D为男性,女性多于男性得到我们要预测的结果为女性。
这样问题就来了,一个女性的脚43码的可能性,远远小于男性脚43码的可能性,那么为什么算法还是会预测F为女性呢?那是因为由于各个特征量纲的不同,在这里导致了身高的重要性已经远远大于脚码了,这是不客观的。所以我们应该让每个特征都是同等重要的!这也是我们要归一化的原因!

归一化后,每个坐标就统一为百分比,不会出现数据差距过大的情况
4 概述
- 算法的总过程:来了一个新的输入实例,我们算出该实例与每一个训练点的距离(这里的复杂度为0(n)比较大,所以引出了下文的kd树等结构),然后找到前k个,这k个哪个类别数最多,我们就判断新的输入实例是哪类!
- 距离:与该实例最近邻的k个实例,这个最近邻的定义是通过不同距离函数来定义,我们最常用的是欧式距离。
- 归一化:为了保证每个特征同等重要性,我们这里对每个特征进行归一化。
- k值:k值的选取,既不能太大,也不能太小,何值为最好,需要实验调整参数确定!
